Es ist eine unangenehme Wahrheit, die gerne übersehen wird: Die Stammdaten sind oft nicht so gut wie man sie gerne hätte. Konkret für das CRS- und FATCA Reporting ist eine sehr hohe Datenqualität notwendig, um korrekte und vollständige Meldungen an die jeweiligen Steuerbehörden zu erzeugen. In der Praxis bleiben oft Datenlücken, deren Behebung aufwendig und kostspielig sein kann. Mit unserer Softwarelösung i:Reg werden diese Lücken rechtzeitig erkannt und können mit den Finanzinstituten behoben werden.
Wir sprechen hier von Datenqualität, genauer gesagt die nicht-immer-ausreichende Datenqualität, und wie diese nachhaltig verbessert werden kann. Speziell für das CRS- und FATCA Reporting ist eine sehr hohe Datenqualität notwendig, um korrekte und vollständige Meldungen an die jeweiligen Steuerbehörden zu erzeugen.
Heutzutage haben die Finanzinstitute klare und umfassende Vorgaben darüber, welche Informationen über ihre Kunden und Kundinnen zu erfassen sind. Manche Vorgaben sind gesetzlich, manche stammen aus internen Prozessen. Die zu früheren Zeiten weniger vorhandenen Vorschriften und Formulare, verursachen heutzutage Herausforderungen in Bezug auf die Vollständigkeit der Stammdaten. Aus der Vergangenheit entstandene Datenlücken werden meist erst beim nächsten Kundentermin, welcher oft in ferner Zukunft liegt, nacherfasst. Beispielsweise gab es in 2015 noch keine Anforderung, für CRS die TIN Verifikation oder die Durchführung einer Plausibilitätsprüfung.
Datenlücken müssen im kernsystem behoben werden
Im Kernsystem eines Finanzinstituts mag es unwesentlich sein, ob für einen Kunden/eine Kundin das eine oder andere Attribut erfasst ist. Aber spätestens in der weiteren Verarbeitung wird die fehlende, aber notwendige Information zum Stolperstein. Weil die unterschiedlichen nachgelagerten Systeme jeweils unterschiedliche Informationen benötigen, wird die Liste jener Attribute sehr lang, die im Kernsystem als Pflichtfeld zu betrachten sind, auch wenn sie im Kernsystem selbst nicht zwingend notwendig wären. Also fängt es schon im Kernsystem an – dort, wo die Kundendaten ursprünglich erfasst werden, gibt es entweder kein Feld für gewisse Informationen, oder diese Felder waren in der Vergangenheit nicht zwingend auszufüllen.
problematik: pflichtfelder
In der Tat sind Pflichtfelder ein zweischneidiges Schwert, denn einerseits soll der Kunde ja gänzlich erfasst werden, andererseits soll die Kundenanlage jedoch zügig gehen und nicht von Details geblockt werden, die auch später nacherfasst werden können – vorausgesetzt natürlich, dass diese Nacherfassungen wirklich gemacht werden. Und vorausgesetzt, dass es dafür auch das passende Feld gibt.
Was auch immer die Ursache sein mag, am Ende bleiben dennoch oft Datenlücken, deren Behebung aufwendig und kostspielig sein kann.
unsere softwarelösung i:Reg erkennt datenlücken in rechtzeitig
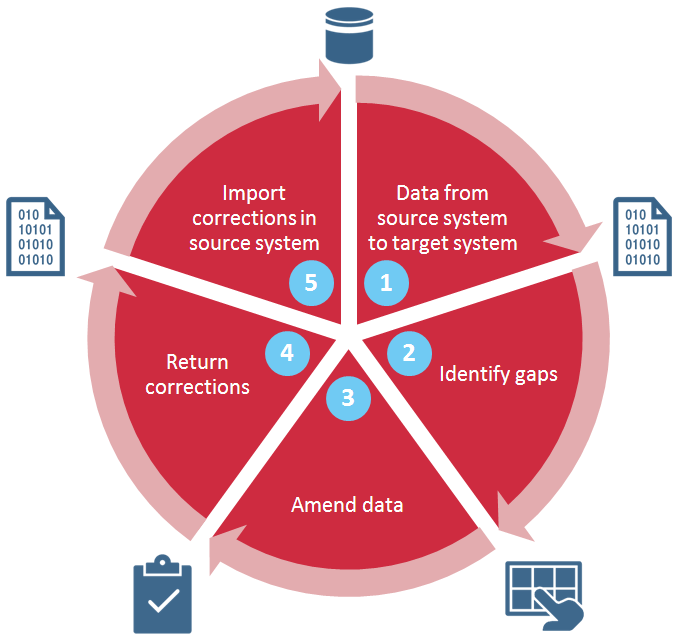
Aufgrund der gesetzlichen Meldeverpflichtungen an internationale Steuerbehörden sind Datenlücken besonders unangenehm, wenn sie eine korrekte Meldung verhindern können. Um die komplexen Meldungen zu erstellen ist es mittlerweile notwendig, ein Softwareprodukt wie i:Reg einzusetzen. Weil i:Reg die Lücken automatisch erkennt und aufzeigt, wird es den Finanzinstituten möglich, diese systematisch zu beheben.
Die Lücken können direkt in i:Reg gefüllt werden (damit zumindest die Meldungen richtig sind), oder aber man leitet diese wertvolle Information zurück an die Datenquelle – so kann die Datenqualität nachhaltig verbessert werden und auch anderen Systemen zu Gute kommen.
fazit
Es zahlt sich aus, die Datenqualität schon direkt bei der Quelle zu korrigieren, um sich immer wiederholende Probleme zu vermeiden und gleichzeitig Kosten zu sparen. In den Worten von John Wooden „If you don’t have time to do it right, when will you have time to do it over?“